Technology
Three Ways Machines Learn from Data: Regression, Classification, and Clustering
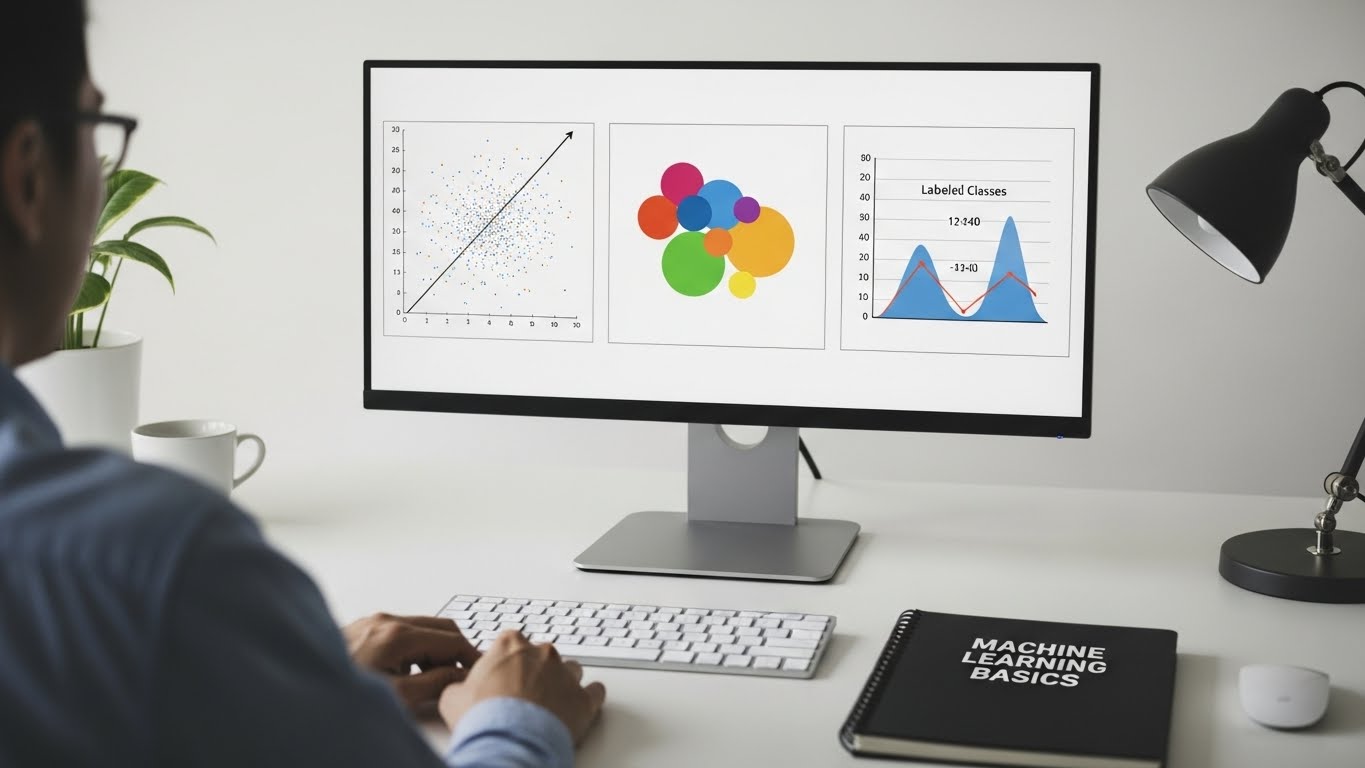
When people talk about machine learning, they often mean three core types of problems: regression, classification, and clustering. These are like three different lenses for looking at data, each answering a different kind of question. Understanding them in simple terms helps you see what’s really happening behind many AI powered tools you use every day.
Regression: Predicting Numbers
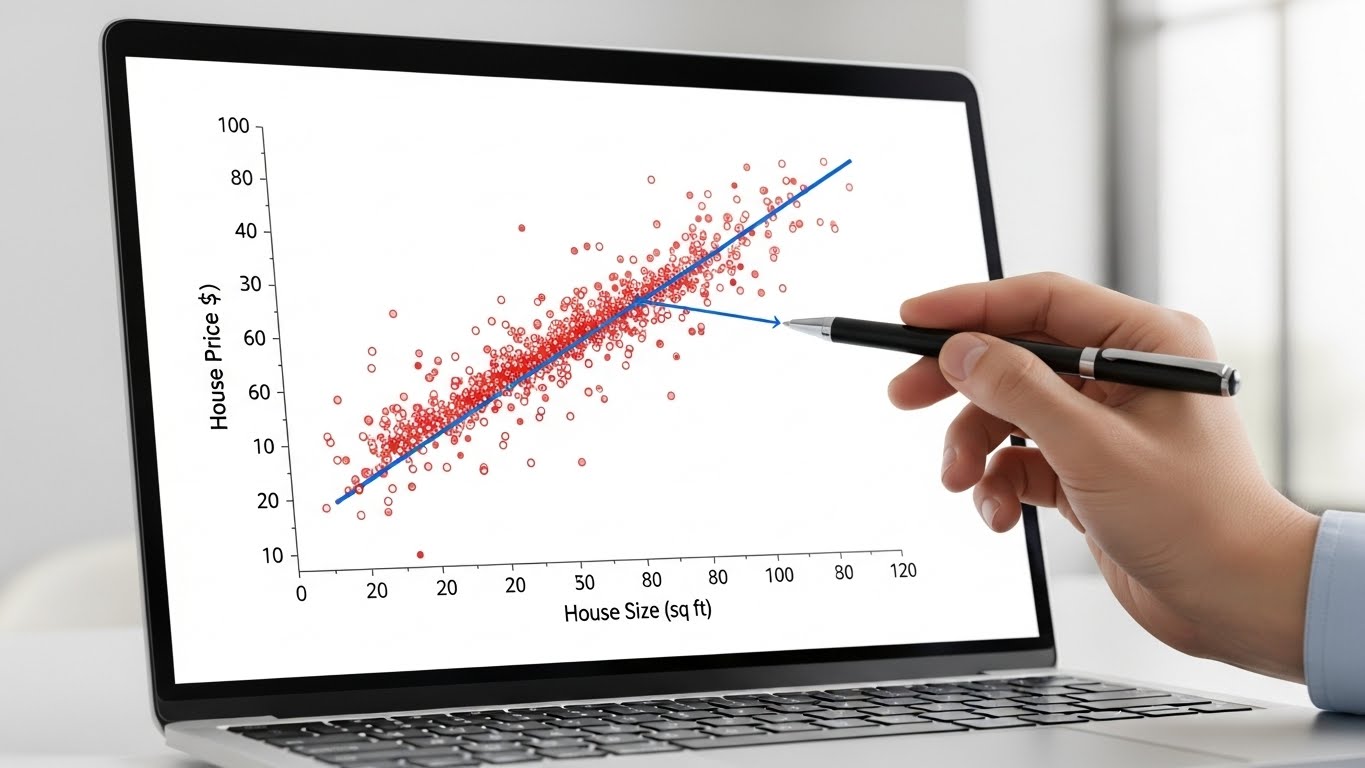
Typical questions it answers are:
- What will the price of this house be?
- How many sales will we have next month?
- What will the temperature be tomorrow?
You give a regression model examples of inputs and the real numbers you want it to learn, such as house size, location, and age, along with the actual selling price. The model then learns a relationship between the inputs and the output. Later, when you provide details of a new house, it estimates the price.
You can think of regression as drawing the “best possible line or curve” through a cloud of points so that new points fall close to that line. It doesn’t say “yes or no” or “type A or B” it predicts how much.
Classification: Sorting into Categories
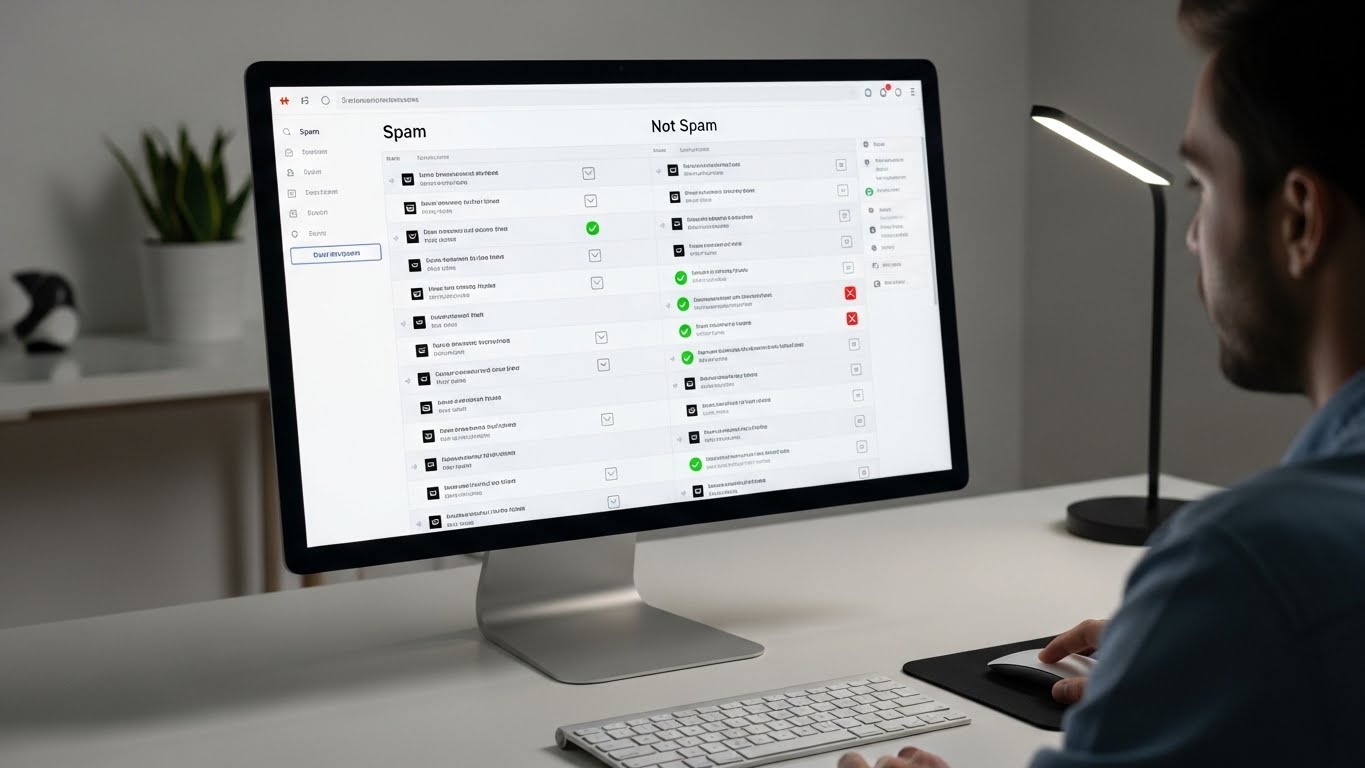
Typical questions it answers are:
- Is this email spam or not spam?
- Is this tumor benign or malignant?
- Which animal is in this photo: cat, dog, or horse?
Here, the outputs are labels, not numbers. During training, the model sees examples with the correct label for instance, many emails already marked as spam or not spam. It learns what patterns usually appear in each category: certain words, senders, or structures.
Later, when a new email arrives, the model compares it to what it has learned and chooses the most likely class. Classification doesn’t tell you how spammy something is in an exact number (although it may use probabilities internally); it tells you which bucket it belongs to.
Clustering: Finding Groups on Its Own

Typical questions it helps with are:
- How many types of customers do we seem to have?
- Are there natural groupings in this dataset?
- Which news articles are like each other?
In clustering, you don’t tell the algorithm what the groups are. Instead, you give it raw data, and it looks for points that are similar. Those similar points are grouped into clusters.
For example, a company might cluster customers based on age, spending habits, and interests. The algorithm might discover three main groups: budget focused buyers, occasional shoppers, and loyal high spenders. The business can then design different marketing strategies for each group even though no one labels these customers beforehand.
How They Fit Together
You can think of three like this:
- Regression: “What number should I expect?”
- Classification: “Which category does this belong to?”
- Clustering: “What groups seem to exist here?”
In real projects, these methods often work side by side. For instance, an online store might:
- Use clustering to discover customer segments.
- Use classification to predict which segment a new customer belongs to.
- Use regression to estimate how much that customer is likely to spend next month.
Even though the math behind them can get complex, the ideas are simple: predict numbers, choose labels, or discover groups. With just these three building blocks, a huge range of intelligent systems from recommendation engines to medical risk tools can be designed in a clear, structured way.
Test Your Knowledge!
Click the button below to generate an AI-powered quiz based on this article.
Did you enjoy this article?
Show your appreciation by giving it a like!
Conversation (0)
Cite This Article
Generating...
.png)
